CNIC has made progress in the research and development of Sparse Operators for Deep Learning and Scientific Computing
Sparse matrix operations are crucial in fields such as deep learning and scientific computing. However, existing unstructured sparse data formats suffer from bottlenecks including complex memory access issues and high format conversion overhead, making it difficult for current GPUs to fully unleash their hardware performance.
The Artificial Intelligence Technology and Application Development Department of the center has designed Acc-SpMV, an efficient sparse matrix-vector multiplication operator tailored for GPU CUDA cores. This research comprehensively considers both the matrix and the right-hand side vector, and effectively overcomes core bottlenecks in traditional methods such as discontinuous memory access and atomic write-back conflicts by adopting matrix reordering, blocking, load balancing, and efficient kernel implementation. Experiments demonstrate that the proposed operator outperforms existing mainstream sparse matrix-vector multiplication operators on CUDA cores and also surpasses implementations on tensor cores in performance benchmarks.
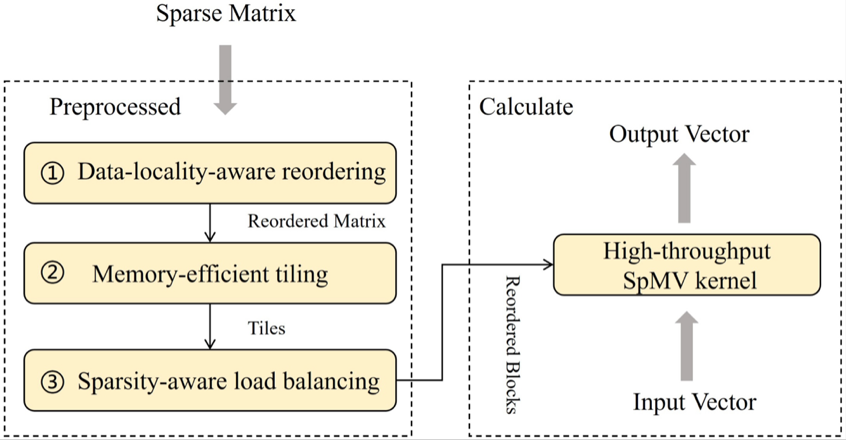
Acc-SpMV Overall Design
We design PillarSparse, an efficient unstructured sparse computing framework for GPU Tensor Cores.By proposing novel sparse data formats and highly efficient pipeline computing kernels, this work effectively addresses key bottlenecks in traditional approaches, such as multi-level memory access latency and excessive format conversion overhead.
Experiments show that PillarSparse outperforms existing mainstream sparse computing libraries across various operator-level performance benchmarks.In end-to-end graph neural network (GNN) training scenarios, it not only achieves significant speedups on full-batch tasks, but also effectively accelerates the Tensor Core solution for real-time small-batch graph sampling training.
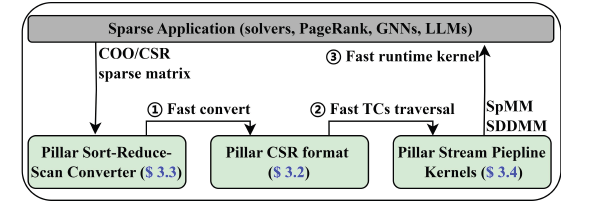
PillarSparse Overall Design
This research has been accepted by the Design Automation Conference (DAC 2026), a CCF-recommended Tier-A international conference. The work was supported by the National Key R&D Program of China and the Strategic Priority Research Program of the Chinese Academy of Sciences.
For the first work, the first author is Tang Lei, a master’s student at the center, and the corresponding author is Dr. Zhou Chunbao, a researcher at the center.For the second work, the first author is Gu Junyu, a PhD candidate at the center, and the corresponding author is Wang Jue, a Senior Engineer at the center.
Related Publications:
[1] Lei Tang, Zhikuang Xin, Zijian Wang, Chunbao Zhou, Jue Wang and Yangang Wang. Acc-SpMV: Accelerating General-purpose Sparse Matrix-Vector Multiplication with GPU CUDA Cores. Proceedings of the 63rd ACM/IEEE Design Automation Conference. 2026.
[2] Junyu Gu, Jue Wang, Zhikuang Xin, Zhiqiang Liang, Zongguo Wang, Hongyu Gao, Peng Di and Yangang Wang. PillarSparse: Rethinking Unstructured Sparse Formats for Tensor Cores. Proceedings of the 63rd ACM/IEEE Design Automation Conference. 2026.