CNIC made progress in building a corpus of large models-enhanced electrocatalytic reduction and synthesis processes
The current boom of pre-trained big language models brings new prospects for domain NLP (Natural Language Processing, NLP) tasks oriented to scientific literature. In collaboration with The National Center for Nanoscience and Technology (NCNST), the Big Data Department of CNIC has constructed an open source dataset of large models-enhanced electrocatalytic reduction and synthesis processes, which can help scientists in the field of catalysis to rapidly discover new efficient catalysts and complete their preparation, and released the LLMs parameters fine-tuned based on the pre-training of the literature in the field of electrocatalysis and the annotated data directives, which can provide model support for other generative tasks in the field of catalytic materials. The research results were published in 《Scientific Data》, A subissue of the journal Nature. Xueqing Chen and Ludi Wang from the Big Data Department of CNIC are the co-first authors of the paper, and researcher Yi Du is the co-corresponding author.
This work was supported by the Young Scientist Project of Key Research and Development Program (KRDP) "Domain Knowledge Graph-based Software for Mining Photoelectrocatalytic Materials" and Information Science Database in National Basic Science Data Center(NBSDC), etc.
The paper links:
https://www.nature.com/articles/s41597-024-03180-9
The corpus links:
https://doi.org/10.57760/sciencedb.13290;
https://doi.org/10.57760/sciencedb.132924;
https://doi.org/10.57760/sciencedb.13293
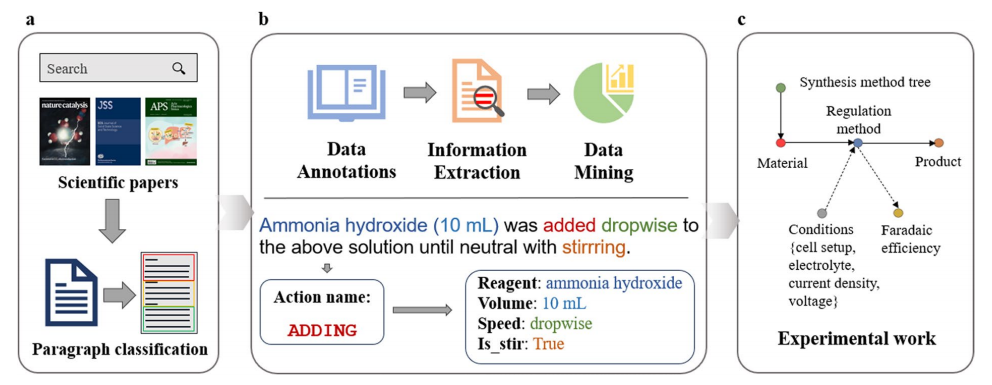
The overall framework of corpus construction and the synthesis process disassembly process.
For more details,please contact Chen Xueqing(xqchen@cnic.cn)